こんにちは、ファンリピートの塙です。
本ブログではepiCRealismとReActorを使った画像生成を行う方法について紹介します!
近年では、個人レベルでもクオリティの高い画像生成が可能になっていますが、+αの工夫を加えることでよりクオリティの高い画像生成が可能になります。そこでより人物の画像生成を高度にさせるモデルを使用した方法と、特定の顔を生成した画像の人物に埋め込む方法について紹介します。
本ブログ作成にあたり、google colab proを使用して制作に取り組みました。
まず、今回画像生成を行うにあたってStable Diffusionというtext to imgができる訓練済みAIモデルを使用します。また、このAIを使用する環境として、「 Stable Diffusio Webui」である「AUTOMATIC1111」を使用しました。
まず、google colab proの購読を行います。無課金の状態では高機能なGPUを使えないため、画像生成には性能が足りません。(そもそもGoogle colab側がStable diffusionの使用はできなくしているという噂もあります。)購読をキャンセルしない限り毎月支払いが行われてしまうので、怖い方は、一度登録後にすぐに購読をキャンセルしてもらって問題ありません。お金を払った1ヶ月はキャンセル後も使用を続けることができます。
続いてgoogle colabにてAUTOMATIC1111の環境をGitからクローンします。
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
続いて、AUTOMATIC1111を実行してみます。
%cd /content/stable-diffusion-webui
!python launch.py --share --enable-insecure-extension-access
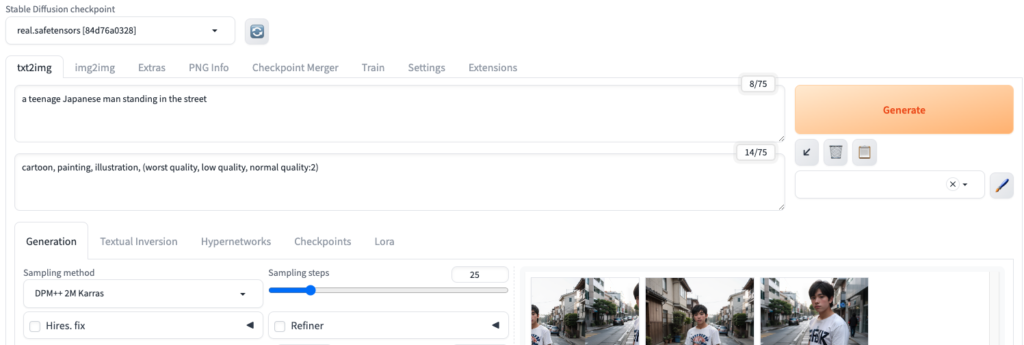
(ベースモデルを使用し、step数25で実行した場合
prompt: a man standing in the street
negative prompt: cartoon, painting, illustration, (worst quality, low quality, normal quality:2))

プロンプトやステップ数では改善可能かもしれませんが、顔があまり綺麗に生成できていないことがわかります。
そこで、人物の画像をより多く学習したモデル「epiCRealism」を追加してみました。このモデルの導入により、より高品質な画像生成ができるはずです。
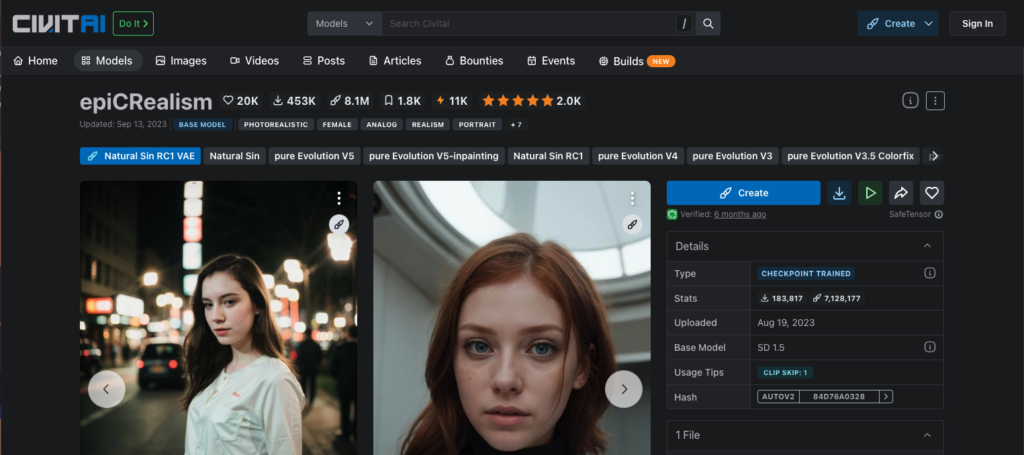
新たなモデルの追加方法ですが、epiCRealismのページの右側にある「1 File」のプルダウンを開くとダウンロードというボタンがありますので、ここでは一旦リンクのみをコピーします。このままダウンロードを行うと約2GBものデータをダウンロードする必要があるためダウンロードに時間がかかってしまいます。
google colabに戻り、もし先ほどのwebuiがまだ動いているのであれば、一旦停止します。
そして、以下のコードを実行し、モデルを直接google colabにダウンロードします。
!wget -P "/content/stable-diffusion-webui/models/Stable-diffusion"[先ほどコピーしたリンク]
この方法でgoogle colab上の環境にモデルを直接ダウンロードすることで自前の回線を使わずにすぐにモデルのダウンロードが可能です。今回の場合2GBものデータがたったの22秒でダウンロードし終えてしまいました)
この際ダウンロードされたファイルのファイル名を確認し、拡張子が.safetensorsとなっているか確認してください。なっていなければ修正してください。修正しないとcheckpointとして認識されません。
新しいモデルを追加した上で再度WebUIを立ち上げ、左上の「Stable Diffusion checkpoint」のプルダウンから今回追加したモデルを確認できるので、そちらを選択してください。
下の図は、同じプロンプト、ステップ数で生成した画像を並べたものですが、ベースモデル(上記)とepiCRealismでは、画像のクオリティに大きな差があることが分かります。

人物の顔がよりクリアになり。街並みもより自然な感じに変わりました。
続いて生成した画像の人物の顔を指定した顔で埋め込みをしてくれるReActorというエクステンションを追加しました。
こちらはモデルではないので、WebUIのExtensionsタブから”Install from URL”にReActorのgithubのURLを追加することで導入しました。
追加するとgenerationタブに新たにReActorのチェックボックスができるのでチェックし、参照させたい画像ファイルを添付します。
弊社の代表で試してみました。
参照画像

生成画像

以前生成した男の子の画像を元にした画像も生成してみました
参照画像

生成画像

なぜか丸顔が出力される傾向にあるようです。
とはいえ、元の写真の顔の面影がかなり反映されているのが分かるかと思います。
今回このブログの作成にあたりネットの情報をいろいろ確認しながら画像生成に取り組んでみましたが、思ったよりも簡単に制作することができました。
まだ、gitを使ったりなどプログラミング全くの未経験者にとってはハードルの高いツールですが、stable diffusionはopen sourceであるため、どんどん使いやすく、ハイレベルな画像生成を誰でもできるツールが開発されるのも近い将来あると思います。また、google colabを活用することで個人のマシンパワーを必要せずに生成が可能な点もかなり便利だなと感じました。