こんにちは!
ファンリピートの佐藤です。ChatGPTが登場してから、AIが世間にどんどん浸透していますね。
そんな中、AIはどういう仕組みで動いているのか個人的に気になり、LLM(大規模言語モデル)の文章生成の仕組みについて調べてみました。
参考書籍
今回、記載する内容にあたって主に参考にしている書籍は以下となります。

LLM(大規模言語モデル)を支える技術
結論として大規模言語モデルが行う文章の生成とは、ある単語の系列の次に来る単語を予測することです。
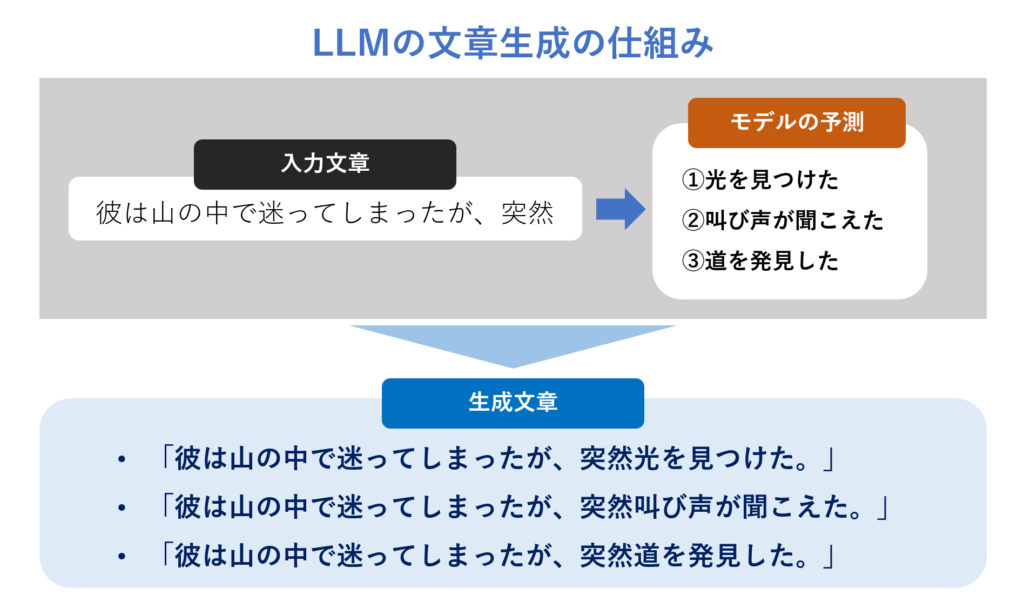
ChatGPTをはじめとしたとした大規模言語モデルに共通して使われているコア技術が2つあります。それは「トランスフォーマー(Transformer)」と自己教師あり学習(Self-supervised Learning)」という2つの技術です。
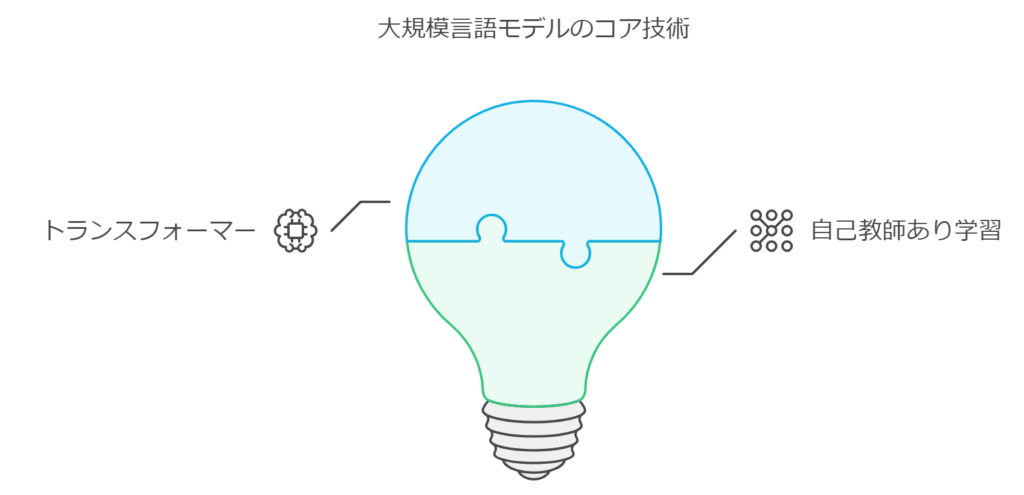
その際に「トランスフォーマー」と「自己教師あり学習」の2つの技術が使われています。
これは、予備校の先生が試験のプロとして問題のパターンを記憶から引き出し、回答するのに似ています。
トランスフォーマーとは?
トランスフォーマーはディープランニング技術のひとつです。 ChatGPTなどが登場する前の従来のディープラーニングでは、うまく文の構造や文脈の要素を捉える精度が不十分でした。
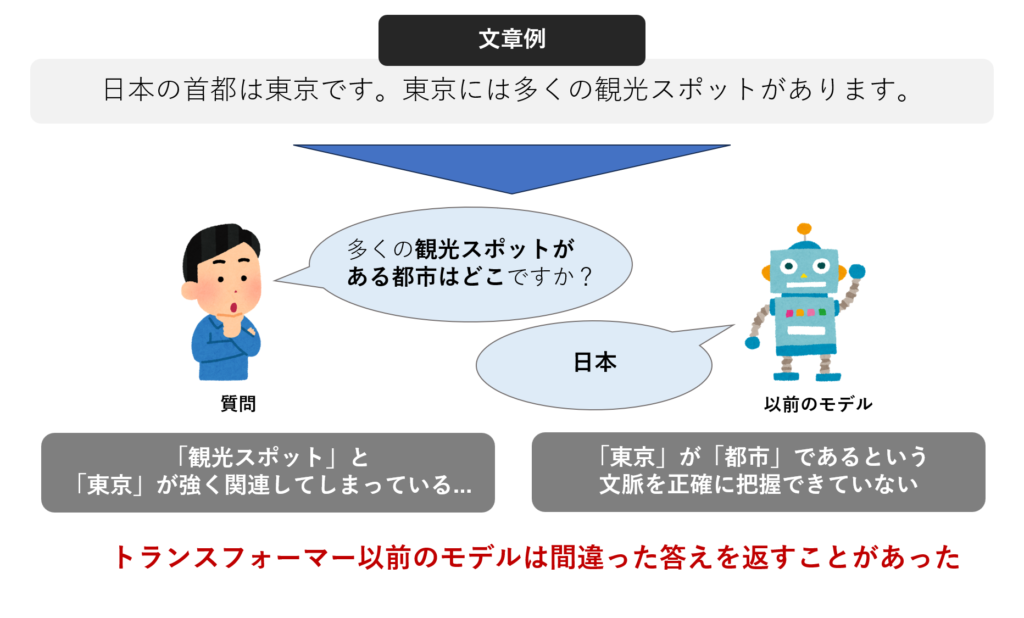
この問題を解決する新たなディープラーニングモデルとして登場したのがトランスフォーマーです。トランスフォーマーで提案された「注意(アテンション,Attention)」という仕組みは、文章の構造や文脈の理解を飛躍的に向上させました。アテンションの仕組みは「自己注意(Self-attention)」と「マルチヘッド自己注意(Multi-head self-attention)」の2つに分けられます。
まず、アテンションとは文章の中で重要な部分に特に注意を払う仕組みのことです。 これは、人が文章を読むときに、特に重要な単語やフレーズに注目するのと似ています。
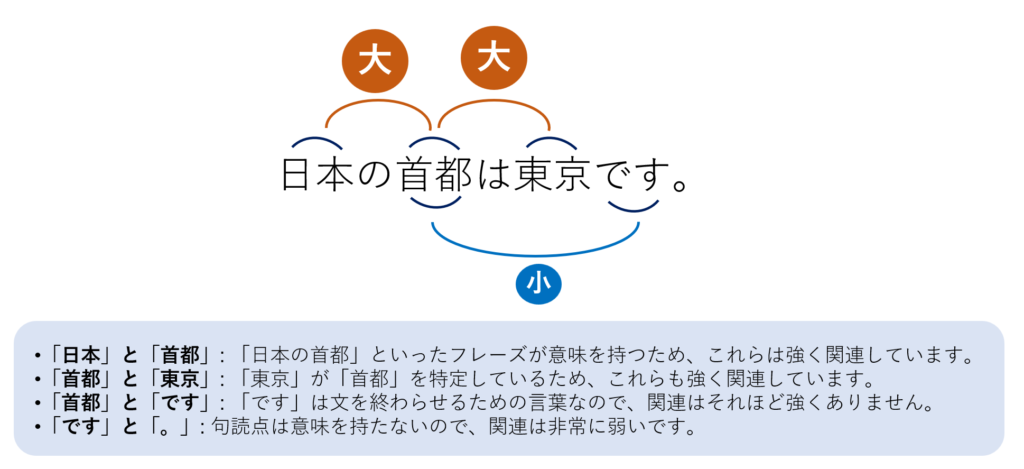
文章の中の単語同士がどれだけ関連しているかを計算します。 例えば、「日本の首都は東京です。」という文を考えてみます。 この文では、「日本」と「首都」、「首都」と「東京」は強く関連しています。 一方、「首都」と「です」や「。」の関連はあまり強くありません。
この自己注意の仕組みによって、長い文章で遠く離れた単語であっても、「これ」「それ」「あれ」といった指示代名詞を表す言葉による依存関係をうまく捉えられます。
マルチヘッド自己注意は、文章を複数の「視点」から理解する方法です。 これにより、同じ文章の異なる側面を同時に捉えることができます。

マルチヘッド自己注意では、自己注意を同時に複数回実行します。それぞれの自己注意は異なる視点から単語間の関係を捉えます。これにより、文章のさまざまな側面を一度に理解できます。
どの視点を使うかは、トランスフォーマーというモデルが自動的にデータから学習します。 たくさんのデータを使ってトランスフォーマーを学習させることで、文章の多様な関係性を理解する能力が向上します。
自己教師あり学習とは
自己教師あり学習は、既存の文章を使って自動的に問題を作り、その問題を解きながら学習する方法です。人間が新しいデータを与えなくても、コンピュータが自分で学習を進められます。作成した問題を解く過程でトランスフォーマーの技術が使われています。

自己教師あり学習では、人間が「質問と回答の組」を用意する必要がありません。 従来の方法では、専門家が正しい答えを用意する必要がありました。例えば、翻訳タスクなら元の文章と翻訳された文章の組を用意する必要がありました。 しかし、自己教師あり学習では、インターネットやデータベースに存在する大量のテキストがそのまま教師データとなります。
トランスフォーマーはテキストデータを読み込みながら、単語同士の関係を捉え、次に来る言葉を予測します。間違っていた場合は、正しい答えに合うように学習の重みを調整します。これを繰り返すことで、モデルは穴埋め問題の達人になります。
まとめ
LLMには主要な技術が2つあることを紹介しました。
技術には仕組みがあって動いているのだと改めて強く感じます。
AIの動く仕組みを必ずしも知る必要はないですが、仕組みを知ることでプロンプトの応用なども考えていきたいですね。