どうも、「プログラムの力でお客様の企業価値を最大化したい」、ファンリピートの竹村です。
今日は、OpenAI Responses API 互換を軸に、OpenAI とローカルLLM(軽量モデル/llama3.2 3B など)をアダプターでスイッチする環境構築チュートリアルをまとめます。
結論から言うと、同じエージェントコードのままプロバイダーを切り替えられる構成を作るのがゴールです。やること自体はシンプルですが、設計の勘所があるのでそこを押さえていきます。
GitHub: https://github.com/taccaya/responses-api-llm-providers.git
詳細なソースコードはGitHubからインストールして試せます。
プロバイダー切り替えだけで運用する完全チュートリアル
同じエージェントコードのまま、OpenAI と ローカルLLMを切り替えて使うための実践ガイド
このチュートリアルでできること
- OpenAI とローカルLLMを同一コードで切り替える構成を作れる
- Responses API 互換の設計ポイント(stateful / stateless)を理解できる
- 最小構成のエージェントとツール連携を再現できる
はじめに
生成AIを使ったアプリケーション開発は、ここ1〜2年で大きく変わりました。単にチャットを呼び出すだけではなく、ツールを使い、状態を持ち、何度も推論を繰り返す「エージェント的な構造」が、実運用の前提になりつつあります。
一方で、多くのチームが次のような悩みを抱えています。OpenAI の API に強く依存していてよいのか、ローカルLLMや社内推論基盤を使いたいが実装が複雑になりそう、プロバイダーが増えるたびに if 文が増えていくのは避けたい、といったものです。
本記事では、こうした悩みに対して「OpenAI Responses API 互換」という軸を中心に、OpenAI と Local LLM(軽量モデル)を、プロバイダー切り替えだけで運用する方法を解説します。
最終的なゴールは明確です。エージェントのコードは一切変えずに、「どこで推論するか」だけを切り替えられる構成を作ることです。
なぜ「Responses API 互換」が重要なのか
APIは、すでに「事実上の標準」になっている
LLMをプログラムから利用するための API には、公式な国際標準は存在しません。しかし現実には、OpenAI が提供してきた API 仕様が事実上の標準(デファクトスタンダード)として広く使われています。SDK が充実しており、サンプルコードや記事が圧倒的に多く、各種フレームワークやツールもこの仕様を前提に作られているためです。
最近登場した OpenAI の Responses API は、従来の Chat API を拡張し、ツール呼び出し、ストリーミング、マルチステップ推論(エージェント)を前提に設計された次世代の API です。今後、エージェント型アプリケーションを構築する上で、この Responses API を前提に考えることは自然な流れと言えるでしょう。
ローカルLLM側も「標準に寄せる」時代に入った
ここで重要なのが、オープンウェイトLLMを扱うためのランタイムである Ollama の動きです。Ollama は、Llama や Qwen、Mistral などのモデルをローカルやサーバー上で簡単に実行・管理するためのツールですが、単にローカルでモデルを動かすだけの存在ではありません。
Ollama は、もともと OpenAI の /v1/chat/completions 互換 API を提供していましたが、v0.13.3 で OpenAI の新しい Responses API(/v1/responses)にも対応しました。OpenAI 互換 API を提供しているため、既存のクライアントやコードを流用しやすい点がメリットです。
この対応により、現在の Ollama では「OpenAI の API を叩いているつもりで、実際にはローカルLLMが動いている」という構成を、現実的に実現できるようになりました。この Responses API 互換は比較的新しいアップデートであり、エージェントやツール呼び出しを前提としたアプリケーションを、ローカル環境や社内サーバーへ持ち込む流れを加速させる重要なポイントです。
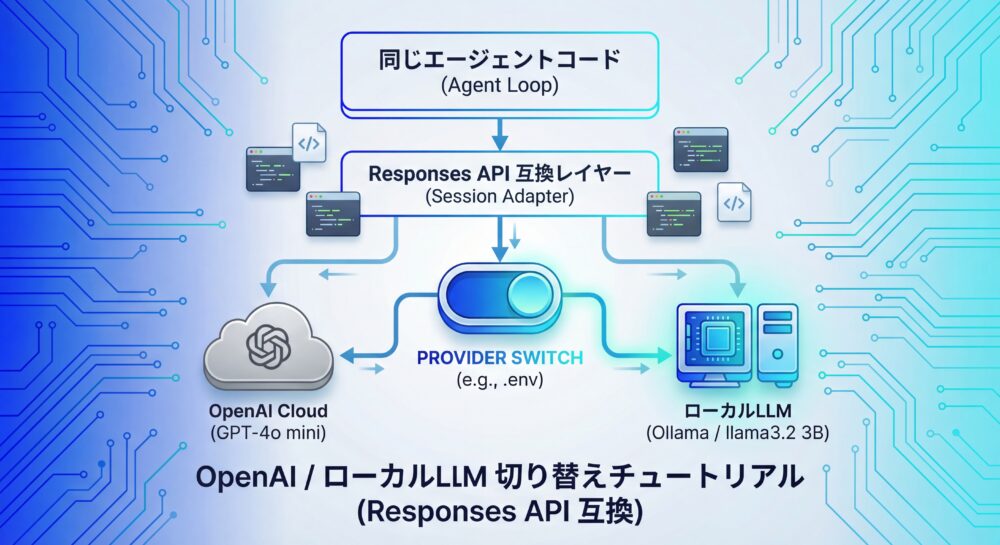
全体像:今回構築するアーキテクチャ
[ Agent Loop ]
|
[ Responses API Session ]
|
+-------------------+
| OpenAI | Ollama |
+-------------------+本記事で構築するアーキテクチャは非常にシンプルです。エージェントの本体ロジックは完全に共通化し、OpenAI とローカルLLMの違いはアダプター層で吸収します。実行時に切り替えるのは、環境変数で指定するプロバイダーだけです。
エージェントループの上に Responses API 互換のセッションを置き、その下で OpenAI または Ollama(Local LLM)が動く、という構造になります。この構成により、OpenAI からローカルLLMへの切り替えだけでなく、将来的に Gemini や社内推論基盤を追加することも容易になります。
ローカルLLMの選択:M2 Mac mini(RAM 8GB)で現実的に強いモデル
このチュートリアルでは、M2 Mac mini / RAM 8GB という現実的なローカル環境で「ちゃんと動いて、しかも賢い」モデルを前提にします。
結論から言うと、3B以下が快適ゾーンです。8Bクラスは理論上動いても、速度・安定性・発熱の観点で実用になりません。
以下は、実際に評価が高く、Ollama で扱いやすいモデルです。
推奨モデル一覧(用途別)
- llama3.2:3b:総合用途の第一候補。軽量だが要約・対話・業務文生成が安定。
- schroneko/gemma-2-2b-jpn-it:日本語特化。自然文・説明文が得意。
- qwen2.5-coder:1.5b:コード補助向け。JS/TS の短い修正や生成に強い。
- qwen2.5:1.5b:とにかく軽く、速度優先。簡易対話や下書き向け。
ローカルLLMと OpenAI モデルの対応イメージ
ローカルLLMは「サイズが小さい=性能が低い」と思われがちですが、用途を絞れば OpenAI の小型モデル相当の体験ができます。以下はあくまで 体感ベース の比較ですが、導入判断には十分役立ちます。
| ローカルLLM(Ollama) | 想定用途 | 体感的に近い OpenAI モデル | コメント |
|---|---|---|---|
| llama3.2:3b | 要約 / 業務文 / 軽いエージェント | gpt-4o-mini | 総合力が高く、まずこれ |
| gemma-2-2b-jpn-it | 日本語説明 / FAQ | gpt-4o-mini(日本語弱め) | 日本語はむしろこちらが自然な場面も |
| qwen2.5-coder:1.5b | コード補助 | gpt-4o-mini(コード短文) | 小修正・補完向き |
| qwen2.5:1.5b | 雑談 / 下書き | gpt-3.5 相当 | とにかく軽い |
※ 正確なベンチマーク対応ではなく、ローカルでの実用体感を基準にしています。
Ollamaのセットアップ(ローカル)
Ollama をインストールした後、次のコマンドでモデルを取得します。
# (ターミナル)
ollama pull llama3.2:3b
ollama run llama3.2:3bを実行し、対話ができることを確認してください。この時点で Ollama はローカルに OpenAI 互換 API サーバを立ち上げています。
.env 設定
.env.example をコピーして .env を作成し、利用するプロバイダーに合わせて設定します。
# openai / ollama
LLM_PROVIDER=ollama
# 1回の起動あたりの最大ターン数
MAX_TURNS=20
# リクエスト間の最小間隔(ミリ秒)
MIN_REQUEST_INTERVAL_MS=1200
# 時刻表示のタイムゾーン(必要に応じて変更)
# TIME_ZONE=Asia/Tokyo
# ツール実行ログを出す場合は 1
LOG_TOOLS=1
# OpenAI
OPENAI_API_KEY=xxxx
OPENAI_MODEL=gpt-4o-mini
# Ollama
OLLAMA_BASE_URL=http://localhost:11434/v1
OLLAMA_MODEL=llama3.2:3b
# コンテキスト長を制限(M2 / RAM 8GBでは非常に重要)
OLLAMA_NUM_CTX=2048</code>プロジェクト構成
教材として理解しやすいように、プロジェクト構成は最小限にしています。Provider 追加方法は providers/README.md にまとめています。
リポジトリ名は responses-api-llm-providers です。
responses-api-llm-providers/
package.json
.env.example
.env
index.mjs
agent.mjs
tools.mjs
providers/
README.md
openai.mjs
ollama.mjsエージェント本体(変更しないコード)
ここが最も重要な部分です。このファイルには、プロバイダー固有の処理は一切書きません。OpenAI であっても、ローカルLLMであっても、同じエージェントループが使われます。
// agent.mjs
export async function runAgent({ session, runTool, userText }) {
let step = await session.sendUser(userText);
while (true) {
if (step.type === "final") {
return step.text;
}
const results = [];
for (const call of step.tool_calls) {
const output = await runTool(call.name, call.args);
results.push({
call_id: call.call_id,
name: call.name,
output,
});
}
step = await session.sendToolResults(results);
}
}ツール定義(最小実装)
tools.mjs はエージェントが呼び出す関数群の定義です。本記事では最小構成として「現在時刻を返す」ツールだけを用意します。
// tools.mjs
export const TOOL_SPECS = [
{
type: "function",
name: "get_time",
description: "Return the current time in UTC and local time.",
parameters: {
type: "object",
properties: {},
additionalProperties: false,
},
strict: true,
},
];
export async function runTool(name, args) {
if (process.env.LOG_TOOLS === "1") {
console.log(`[tool] ${name} args=${JSON.stringify(args)}`);
}
switch (name) {
case "get_time": {
const now = new Date();
const timeZone =
process.env.TIME_ZONE || Intl.DateTimeFormat().resolvedOptions().timeZone;
const local = new Intl.DateTimeFormat("ja-JP", {
timeZone,
year: "numeric",
month: "2-digit",
day: "2-digit",
hour: "2-digit",
minute: "2-digit",
second: "2-digit",
hour12: false,
}).format(now);
return {
utc_iso: now.toISOString(),
local,
time_zone: timeZone,
};
}
default:
throw new Error(`Unknown tool: ${name}`);
}
}OpenAI用アダプター(Responses API)
ここでは、OpenAI の Responses API を利用するためのアダプターを実装します。OpenAI 側は stateful な会話をサポートしているため、previous_response_id を使って会話を継続します。
// providers/openai.mjs
import OpenAI from "openai";
export function createOpenAISession({ model, toolSpecs }) {
const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
let previous = null;
async function call(input) {
const r = await client.responses.create({
model,
input,
tools: toolSpecs,
tool_choice: "auto",
store: true,
...(previous ? { previous_response_id: previous } : {}),
});
previous = r.id;
const calls = r.output
.filter(i => i.type === "function_call")
.map(i => ({
call_id: i.call_id,
name: i.name,
args: JSON.parse(i.arguments),
}));
if (calls.length) return { type: "tool_calls", tool_calls: calls };
return { type: "final", text: r.output_text };
}
return {
sendUser: (t) => call(t),
sendToolResults: (items) =>
call(items.map(r => ({
type: "function_call_output",
call_id: r.call_id,
output: JSON.stringify(r.output),
}))),
};
}ローカルLLM用アダプター(Ollama)
Ollama の Responses API 互換は non-stateful であるため、会話履歴はアダプター側で保持します。
// providers/ollama.mjs
import OpenAI from "openai";
export function createOllamaSession({ model, toolSpecs }) {
const client = new OpenAI({
baseURL: process.env.OLLAMA_BASE_URL || "http://localhost:11434/v1",
apiKey: "ollama",
});
const history = [];
async function call() {
const r = await client.responses.create({
model,
input: history,
tools: toolSpecs,
tool_choice: "auto",
});
const calls = r.output
.filter(i => i.type === "function_call")
.map(i => ({
call_id: i.call_id,
name: i.name,
args: JSON.parse(i.arguments),
}));
if (calls.length) return { type: "tool_calls", tool_calls: calls };
return { type: "final", text: r.output_text };
}
return {
async sendUser(text) {
history.push({ role: "user", content: text });
const step = await call();
if (step.type === "final") {
history.push({ role: "assistant", content: step.text });
}
return step;
},
async sendToolResults(results) {
history.push(...results.map(r => ({
type: "function_call_output",
call_id: r.call_id,
output: JSON.stringify(r.output),
})));
const step = await call();
if (step.type === "final") {
history.push({ role: "assistant", content: step.text });
}
return step;
},
};
}プロバイダー切り替え
最後に、環境変数でプロバイダーを切り替えるだけのエントリーポイントを用意します。
// index.mjs
import "dotenv/config";
import readline from "node:readline/promises";
import { stdin as input, stdout as output } from "node:process";
import { runAgent } from "./agent.mjs";
import { runTool, TOOL_SPECS } from "./tools.mjs";
import { createOpenAISession } from "./providers/openai.mjs";
import { createOllamaSession } from "./providers/ollama.mjs";
const provider = (process.env.LLM_PROVIDER || "ollama").toLowerCase();
let session;
if (provider === "openai") {
session = createOpenAISession({
model: process.env.OPENAI_MODEL || "gpt-4o-mini",
toolSpecs: TOOL_SPECS,
});
} else if (provider === "ollama") {
session = createOllamaSession({
model: process.env.OLLAMA_MODEL || "llama3.2:3b",
toolSpecs: TOOL_SPECS,
});
} else {
throw new Error(`Unsupported LLM_PROVIDER: ${provider}`);
}
const MAX_TURNS = Number(process.env.MAX_TURNS || 20);
const MIN_REQUEST_INTERVAL_MS = Number(process.env.MIN_REQUEST_INTERVAL_MS || 1200);
const rl = readline.createInterface({ input, output });
let turns = 0;
let lastRequestAt = 0;
console.log("Type 'exit' or 'quit' to stop.");
while (true) {
const userText = await rl.question("You> ");
const trimmed = userText.trim();
if (!trimmed || trimmed.toLowerCase() === "exit" || trimmed.toLowerCase() === "quit") {
break;
}
if (turns >= MAX_TURNS) {
console.log(`Reached MAX_TURNS=${MAX_TURNS}. Set MAX_TURNS to continue.`);
break;
}
const now = Date.now();
const waitMs = Math.max(0, MIN_REQUEST_INTERVAL_MS - (now - lastRequestAt));
if (waitMs > 0) {
await new Promise(resolve => setTimeout(resolve, waitMs));
}
lastRequestAt = Date.now();
const answer = await runAgent({
session,
runTool,
userText: trimmed,
});
console.log(`AI> ${answer}`);
turns += 1;
}
rl.close();これで、OpenAI と ローカルLLMを同じエージェントコードのまま切り替えて利用できるようになりました。
実際に実行して試す
# OpenAI を使う場合
export LLM_PROVIDER=openai
node index.mjs
# Ollama を使う場合(別ターミナルで ollama run を起動)
export LLM_PROVIDER=ollama
node index.mjs
対話は exit / quit で終了できます。OpenAI を使う場合は、連続リクエストが料金増やレート制限の原因になり得るため、以下の制限を用意しています。
MAX_TURNS(既定: 20): 1回の起動あたりの最大ターン数MIN_REQUEST_INTERVAL_MS(既定: 1200ms): リクエスト間の最小間隔
必要に応じて .env で調整してください。時刻表示は TIME_ZONE を指定すると任意のタイムゾーンに合わせられます。
補足:社内サーバーで安全に運用する場合
実運用では、Ollama を個人のPCではなく、社内サーバーにインストールして利用するケースも多いでしょう。その場合は、Nginx や Caddy などのリバースプロキシを前段に置き、Bearer Token 認証や IP 制限、TLS を組み合わせて安全に運用するのが一般的です。
この構成にしておけば、クライアント側では baseURL を社内サーバーの URL に変更するだけで済み、エージェントのコードやアダプターを修正する必要はありません。
RAM 8GB を超えたら:次に選ぶモデル(展望)
もし将来、RAM が 16GB 以上になる、あるいは社内サーバーや別マシンで推論できるようになれば、次のクラスのモデルが現実的になります。
- Llama 3.1 / 3.2 7B:総合力が一段上がり、エージェントの安定性が向上
- Qwen2.5 7B:多言語・コード・推論のバランス型(中国系の有力候補)
- DeepSeek 系 7B:推論寄りタスクの検証対象
本チュートリアルの設計(Responses API 互換+アダプター分離)を採っていれば、モデルサイズが上がっても コードは一切変えず、モデル名を差し替えるだけで対応できます。
補足:公式仕様・互換性・ベンチマーク(参考リンク)
以下は本記事の前提となる一次情報です。ベンチマークは評価条件や指標が異なるため、単純比較ではなく「傾向の把握」に使うことを推奨します。
OpenAI Responses API
- 公式リファレンス(/v1/responses、入力形式、stateful 会話、ツール指定など)
- 設計意図と背景(stateful 前提の設計、ツール統合、評価・キャッシュ改善の説明)
- ツールガイド(Web検索、ファイル検索、Code Interpreter、Computer Use、MCP など)
Ollama の OpenAI 互換
- OpenAI 互換 API(/v1/responses は non‑stateful のみ対応)
- tools 対応の経緯
モデル情報とベンチマーク
- GPT‑4o mini モデル情報(コンテキスト長や対応モダリティ)
- GPT‑4o mini 公式発表(ベンチマークや価格)
- Llama 3.2 3B(Ollama モデルカード)
- Gemma 2 JPN IT(Hugging Face モデルカード)
- Qwen2.5 1.5B(Hugging Face モデルカード)
- Qwen2.5‑Coder 技術レポート(arXiv)
おわりに
このチュートリアルで伝えたかった本質は、ローカルLLMを使うことの価値は「モデルを変えること」ではなく、「標準APIの上に載せること」にある、という点です。
OpenAI Responses API 互換という共通言語を使うことで、クラウド、ローカル、社内推論基盤を同一のエージェント設計で扱えるようになります。これは短期的な最適化ではなく、数年スパンで効いてくる設計判断です。
ぜひ、この構成をベースに、自分たちのユースケースへ広げてみてください。
弊社では、内製開発の支援に加え、こういったAIエージェントを社内のセキュアな環境で動かせるようにするための構築支援も行っています。
最新のLLMを活用した開発効率化をクライアントに提供し、企業価値の最大化を実現する——という弊社のミッションに共感いただけるエンジニアの方、コンサルタントの方は、ぜひ、お問い合わせフォームから、カジュアル面談にご応募ください。